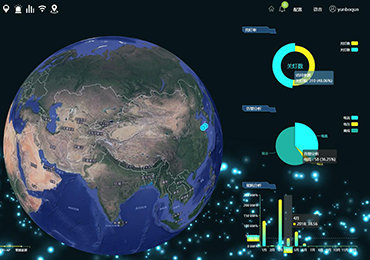
想必许多有心人已经注意到了,如今足球预测的底层逻辑已从经验主义转向数据科学与人工智能的交叉战场,其核心挑战在于如何将动态博弈中的不确定性转化为可量化、可解释的决策因子。而当前主流预测模型依赖三大支柱:多模态数据融合、动态概率建模与可解释性增强,三者共同构成现代足球预测的“技术三角”。
数据源的广谱性与时效性是预测精度的第一性原理。传统分析依赖基础赛事数据(如射门、控球率),但高阶指标如预期进球值(xG)、压迫强度(PPDA)及攻防转换速率(TPP)已成为AI模型的核心输入。以2023-24赛季西甲为例,皇马通过提升反击场景的xG链构建效率(即连续传递对进球概率的累积贡献),使其场均实际进球数超出统计预测值12%,凸显单一数据维度的局限性。更前沿的系统已整合生物力学传感器数据(如球员肌肉负荷状态)与卫星气象信息(如降雨对长传成功率的影响),通过图神经网络(GNN)构建多维关联图谱,识别传统方法难以捕捉的“隐性变量”。
动态建模能力直接决定预测系统的实战价值。足球比赛的马尔可夫性质(即下一状态仅依赖当前状态)要求模型实时更新概率权重。例如,基于强化学习(RL)的决策框架可在比赛中动态调整策略:当利物浦的边路突破成功率下降时,系统即时调用历史数据中相似场景下的替代方案(如阿诺德内收中路后的斜传威胁),并结合实时体能数据评估可行性。德甲门兴格拉德巴赫的技术团队曾利用时序卷积网络(TCN),在比赛第70分钟后将防守反击触发阈值从xG>0.15调整为xG>0.12,以应对对手体能滑坡期的防线漏洞,该策略使球队该时段进球效率提升19%。
然而,技术狂欢背后潜藏认知陷阱。过度依赖黑箱模型可能导致“算法暴政”——2022年世界杯小组赛中,某AI系统因训练数据缺乏“超级球星单点爆破”样本,低估梅西在阿根廷vs墨西哥一战的个人影响力,导致预测结果偏离实际。这揭示可解释性AI(XAI)的必要性:通过SHAP值分析与局部代理模型(LIME),从业者可追溯关键决策节点。例如,巴萨教练组发现,模型对佩德里中场持球时长的权重分配过高,却忽视其无球跑动创造的防守弱侧空间,这种偏差需通过特征工程进行纠偏。
伦理与创新的平衡是另一深层命题。数据驱动预测可能扼杀战术突变带来的“尾部收益”,例如2021年欧洲杯意大利放弃传统链式防守,改用高风险的纵向传递策略,使多数基于历史数据的模型失效。为此,领先机构引入对抗生成网络(GAN),模拟非对称战术场景下的概率分布,同时设立“人类否决权”机制——当教练的临场洞察与模型结论冲突时,系统启动贝叶斯假设检验,评估创新策略的统计显著性。
未来的足球预测将走向量子增强学习与多模态实时感知的融合。例如,通过量子退火算法优化百万级变量的组合决策,或利用计算机视觉直接解析比赛视频流中的阵型相位变化。但技术演进始终需回归足球的本质:它既是数据定义的精确系统,也是人类意志书写的神迹——或许正如克鲁伊夫所言,“预测足球的终极难题,在于如何计算那些拒绝被计算的瞬间”。